반응형
저번 시간에 이어서 이제 데이터를 읽어 와서 구조화 시키는 부분을 만들어 보자 .
https://qwoowp.tistory.com/75?category=817494
주식 배당금 데이터 크롤링(crawling) 하기 (1)
문득 자동으로 배당금 데이터를 가져와서 내 입맛에 맞게 조정을 해서 원하는 종목을 뽑을 수 있을까? 에서 시작해서 공부해 봅니다. 예전에 했던 것들 다 까먹어서 다시 pyCharm 부터 Create Project
qwoowp.tistory.com
https://qwoowp.tistory.com/76?category=817494
주식 배당금 데이터 크롤링(crawling) 하기 (2)
전 글에서 pyCharm 에서 기본 코드를 이용해서 배당금 홈페이지를 띄우는 것 까지 완성 하였다. https://qwoowp.tistory.com/75?category=817494 주식 배당금 데이터 크롤링(crawling) 하기 (1) 문득 자동으로 배..
qwoowp.tistory.com
조회된 데이터를 개발자 도구로
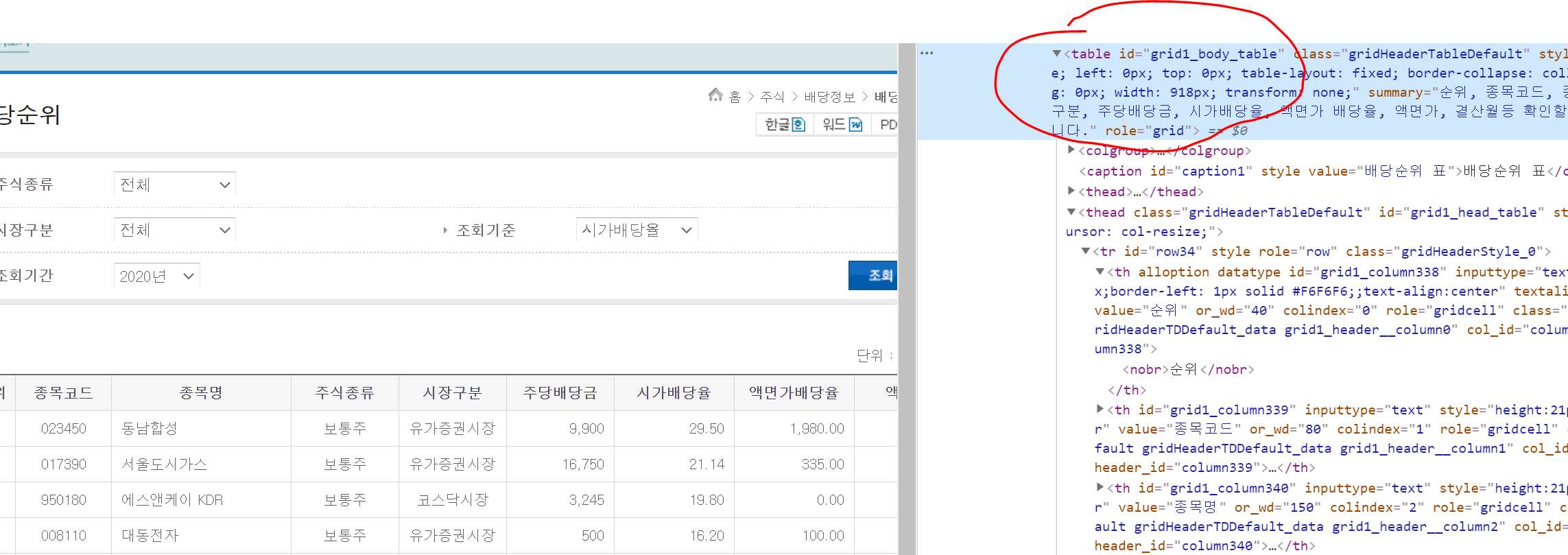
데이터가 있는 테이블을 선택하게 되면 테이블 시작 부분을 알 수 있게 된다.
데이터화 하기 위해서 아래 패키지를 하나더 설치 한다.
pip install pandas

이 형식으로 응용하여 각 페이지를 눌러서 5페이지 양을 가져오도록 하였다.
# html 파싱을 하기 위해서 필요
from bs4 import BeautifulSoup
from selenium import webdriver
# data frame 으로 표데이터를 저장하기 위해서 필요
import pandas as pd
import time
# 문자열 태그 제거를 위해 필요
import re
import string
# 태그를 제거 하기 위한 함수
def remove_tag(content):
cleanr = re.compile('<.*?>')
cleantext = re.sub(cleanr, '', content)
return cleantext
# 년도를 입력하면 원하는 데이터를 조회해서 데이터로 저장하는 함수
# 1. 해당 연도로 검색을 실시
# 2. 해당 페이지에서 15개 데이터를 가져와서 저장
# 3. 페이지 이동 or 현재 페이지가 5페이지 이면 저장 종료 (데이터 가져오는 조건은 변경 가능)
# 4. 1번으로 이동하여 처리
def getdata_dividend(driver, iYear, page):
print(iYear + " Search data...")
# for debugging 윈도우 타이틀 확인하기
print(driver.title)
# 원하는 년도 데이터를 조회한다.
driver.find_element_by_id('selectbox2_input_0').send_keys(iYear)
driver.find_element_by_id('image1').click()
time.sleep(1) # 조회가 완료 될 때 까지 시간을 좀 기다려 줘야 한다.
if page > 1:
# 페이지 이동을 추가로 해야 된다.
page_move_id = "cntsPaging01_page_" + str(page)
print(page_move_id)
driver.find_element_by_id(page_move_id).click()
time.sleep(1)
# 데이터 가져오기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# 원하는 결과가 있는 쪽 결과만 가져온다.
tbody = soup.find(id="grid1_body_tbody")
trs = tbody.find_all("tr")
# 가져온 종목 개수 확인 (한 페이지에 15개 나옴)
print(len(trs))
dic_key = (page - 1) * 15
result_df = pd.DataFrame(columns=range(11))
for tr_data in trs:
# td 안에 nobr 테그로 또 감싸져 있기 때문에 nobr 로 검색하여 가져옴.
tds = tr_data.find_all("nobr")
# tds = remove_tag(str(tds))
# print(arr_tds)
# 인덱스, 종목코드, 종목명, 주식종류, 시장구분, 주당배당금, 시가배당율, 액면가배당율, 액면가, 결산월
# print(len(tds)) # (항목은 10개가 나옴)
tds[0] = remove_tag(str(tds[0]))
tds[1] = remove_tag(str(tds[1]))
tds[2] = remove_tag(str(tds[2]))
tds[3] = remove_tag(str(tds[3]))
tds[4] = remove_tag(str(tds[4]))
tds[5] = remove_tag(str(tds[5]))
tds[6] = remove_tag(str(tds[6]))
tds[7] = remove_tag(str(tds[7]))
tds[8] = remove_tag(str(tds[8]))
tds[9] = remove_tag(str(tds[9]))
df = pd.DataFrame(columns=range(10))
df.loc[dic_key] = [tds[0], tds[1], tds[2], tds[3], tds[4], tds[5], tds[6], tds[7], tds[8], tds[9]]
dic_key = dic_key + 1
#최종 결과에 저장한다. 여기는 Key 값이 들어가서 11개의 column 이 된다.
result_df = result_df.append(df)
# print(dic)
# DF 로 Excel 저장
print(result_df)
# 저장된 데이터를 가지고 원하는 배당금 종목 조건을 검색하여 추출하는 함수
def calcdata_dividend():
print('calc data')
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print('Start Dividend Data crawling')
## Chrome의 경우 | 아까 받은 chromedriver의 위치를 지정해준다.
driver = webdriver.Chrome('C:\_99_joon\python_dividend\chromedriver_win32\chromedriver.exe')
## 크롬 브라우저가 실행될 시간을 위해 5초 정도 기다려 준다.
driver.implicitly_wait(5)
# 원하는 홈페이지 주소 (배당금 순위를 연도별로 조회할 수 있는 곳으로 이동한다.)
driver.get('https://seibro.or.kr/websquare/control.jsp?w2xPath=/IPORTAL/user/company/BIP_CNTS01042V.xml&menuNo=286')
for i_page in range(5):
getdata_dividend(driver, "2019년", i_page+1)
반응형
'Development > Python' 카테고리의 다른 글
| Visual Studio Code 에서 Python 빌드 환경 설정하기 (0) | 2022.09.02 |
|---|---|
| 주식 배당금 데이터 크롤링(crawling) 하기 (4) (0) | 2021.06.03 |
| python 오브젝트 문자열 변환 (object to string) (0) | 2021.06.03 |
| 주식 배당금 데이터 크롤링(crawling) 하기 (2) (0) | 2021.06.01 |
| 주식 배당금 데이터 크롤링(crawling) 하기 (1) (0) | 2021.06.01 |



댓글